i. Overview
The work spanned three training phases — Domain Adaptation, Supervised Fine-Tuning, and Direct Preference Optimization — running on H100 80GB GPUs against curated Dutch corpora. The headline number: a 63 percentage-point jump in B1 compliance, from 12.4% baseline to 75.6% with Mistral-Small-24B + DPO.
Klinkende Taal / SlimTaal, 2025.
ii. Evaluation & Model Selection
I designed and implemented a comprehensive evaluation system to identify the optimal base model for fine-tuning:
- Built a multi-service evaluation platform (Java/Spring Boot + Kotlin) comparing 36 LLMs across 4 providers (Mistral, OpenAI, Groq, Nebius).
- Developed an LLM-as-judge framework with 4 specialised judges evaluating data correctness, style guide compliance, quality adherence, and content rules.
- Integrated the Klinkende Taal API for automated B1 / B2 language complexity scoring.
- Achieved 75.6% B1 compliance with Mistral-Small-24B + DPO, up from a 12.4% baseline (≈12% to 76%) — a 63 percentage-point improvement.

iii. Fine-Tuning Pipeline
I developed a complete ML pipeline for training language models on simplified Dutch:
- Implemented three-phase training: Domain Adaptation, Supervised Fine-Tuning (SFT), and Direct Preference Optimization (DPO).
- Built async data pipelines processing 160k+ Wikipedia sentences through B1 filtering and LLM quality assessment.
- Developed curriculum learning approaches with 43k preference pairs sorted by difficulty gap.
- Deployed training infrastructure on Nebius H100 80GB GPUs using the Axolotl framework.
- Created SGLang and vLLM inference pipelines for high-throughput model evaluation.

iv. Synthetic Data Generation
Real training data for government correspondence is privacy-sensitive, requiring synthetic alternatives:
- Built LetterProcessing for standardising and pseudonymising correspondence templates.
- Developed SyntheticLetters pipeline generating DPO training pairs from templates.
- Created 36k combined training examples (32k sentence pairs + 5.3k letter pairs).
- Implemented quality filtering with automatic rejection of ambiguous or low-quality pairs.
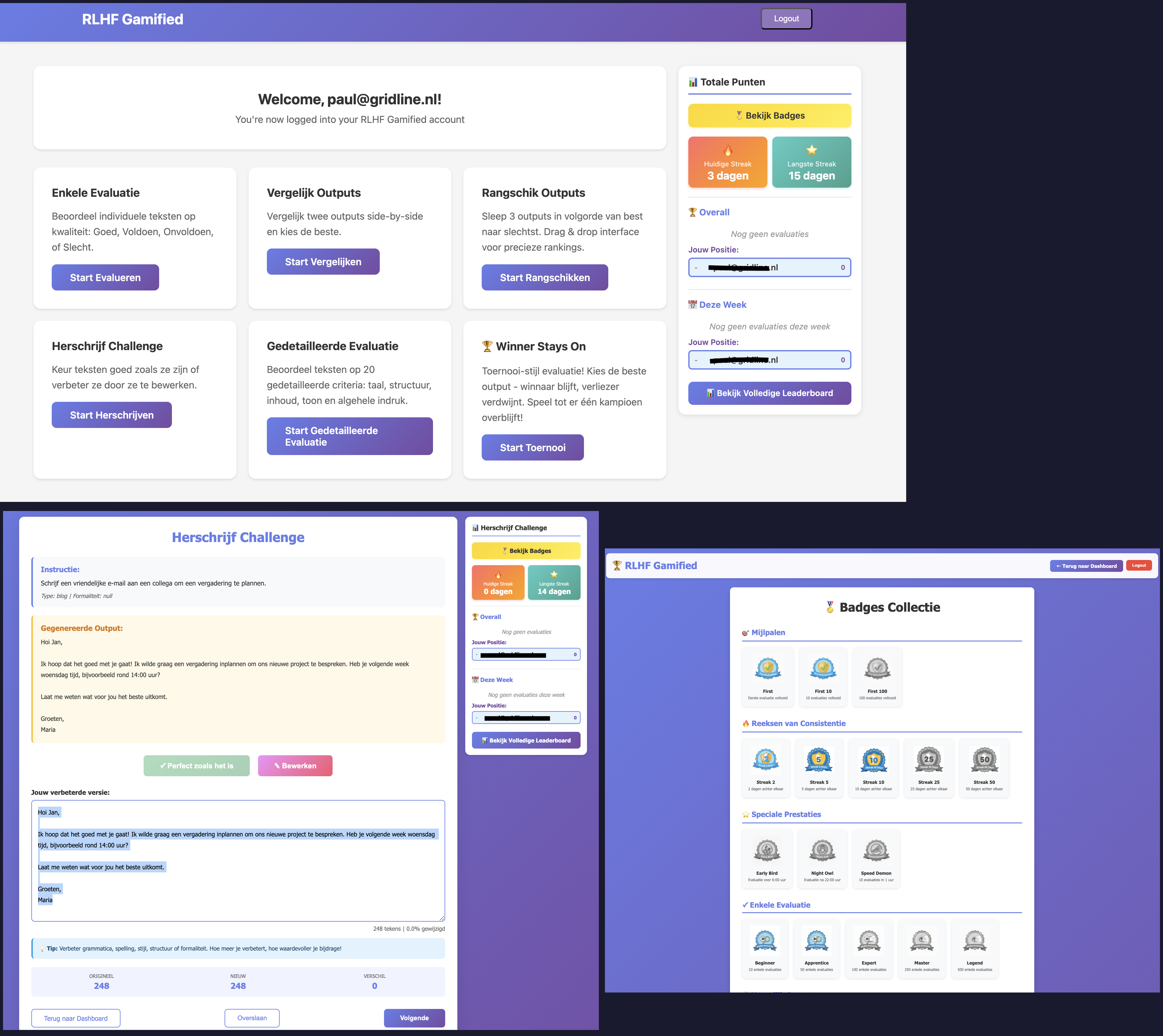
v. Human Feedback Platform
To continuously improve model outputs, I built the LveRLHF expert feedback system:
- Developed a gamified web platform for language experts to evaluate model outputs.
- Implemented Kubernetes deployment with secure authentication for domain-restricted access.
- Created API infrastructure for batch loading evaluation data and collecting feedback.
- Deployed at expertportaal.slimtaal.nl for production use by Lve language specialists.
vi. Key Contributions
- Established the complete ML infrastructure for B1 language model development.
- Identified Mistral-Small-24B as the optimal base model through rigorous comparative study.
- Built reusable evaluation frameworks with objective metrics for language complexity.
- Created comprehensive documentation enabling knowledge transfer to the wider team.
- Developed privacy-preserving synthetic data generation for sensitive government correspondence.
vii. Stack
PythonJavaKotlinSpring Boot
PyTorchAxolotlvLLMSGLang
DPOSFTDomain Adaptation
H100 GPUsNebius
PostgreSQLFlyway
MistralOpenAIGroq
KubernetesDocker
Async pipelines